1. 데이터 이해
1-1. 데이터의 이해
1-2. 데이터의 가치와 미래
1-3. 가치 창조를 위한 데이터 사이언스와 전략 인사이트
2. 데이터 분석 기획
2-1. 데이터 분석 기획의 이해
2-2. 분석 마스터 플랜
3. 데이터 분석
3-1. R 기초와 데이터 마트
3-2. 통계분석
3-3. 정형 데이터 마이닝
3-3-1. 데이터 마이닝 개요
3-3-2. 분류 분석
3-3-3. 군집 분석
3-3-4. 연관 분석
분류 분석
로지스틱 회귀모형
신경망 모형
의사결정나무 모형
앙상블 모형
분류 모형 평가
앙상블 모형
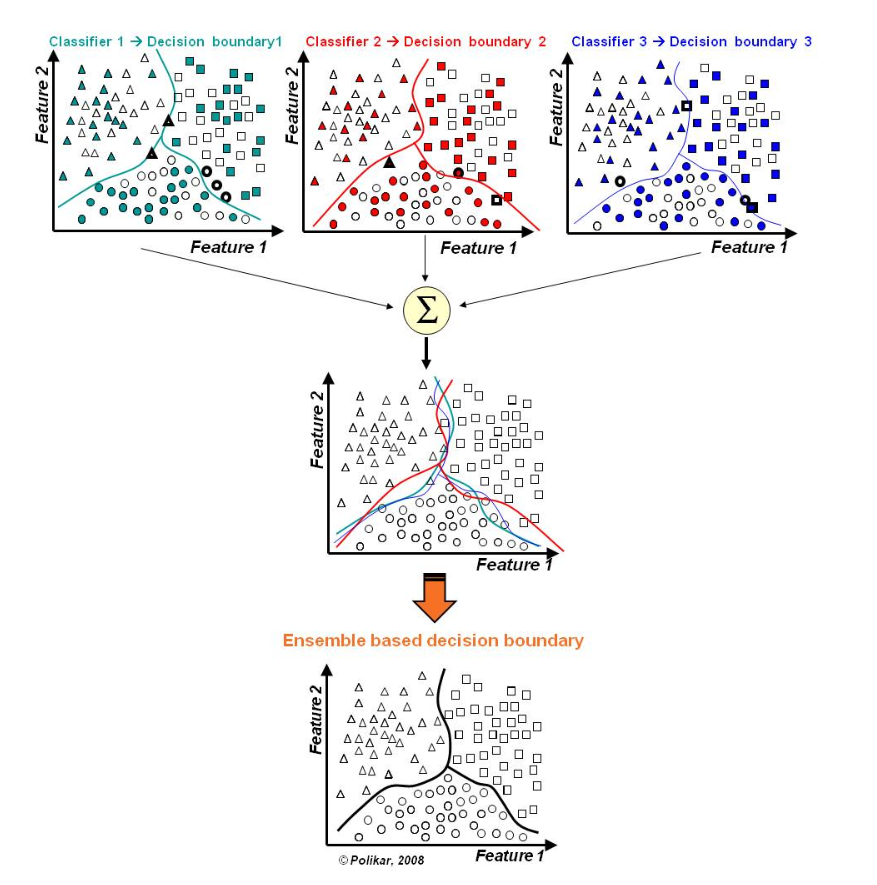
#앙상블 모형의 정의와 특징
- 여러 개의 분류모형에 의한 결과를 종합하여 분류의 정확도를 높이는 방법
- 분리 분석의 과적합을 줄이기 위해 개발
- 적절한 표본추출법으로 여러 개의 훈련용 데이터를 만들고, 훈련용 데이터마다 하나의 분류기를 만들어 앙상블하는 방법
#학습의 불안정성
- 작은 병화에 의해 예측 모형이 크게 변하는 경우, 그 학습 방법은 불안정
- 가장 안정적인 방법: K-최근접이웃, 선형회귀 모형
- 가장 불안정한 방법: 의사결정 나무

#배깅(bagging)
- 원 데이터 집합으로부터 크기가 같은 표본을 여러 번 단순 임의 복원추출하여 각 표본(붓스트랩 표본)에 대해 분류기를 생성한 후 그 결과를 앙상블하는 방법
- 붓스트랩(bootstrap): 주어진 자료에서 동일한 크기의 표보을 랜덤복원추출로 뽑은 자료
- 보팅: 여러 개의 모형으로부터 산충된 결과를 다수결에 의하여 최종 결과를 선정하는 과정
- 가지치기를 하지 않고 최대한 성장한 의사결정 나무들 사용
- 평균예측 모형을 못 구함 (훈련 자료의 모집단의 분포 모름)
- 훈련자료를 모집단으로 생각하고 평균예측모형을 구한 것과 같음 (분산을 줄이고 예측력 향상)
- 반복추출 방법으로 동일한 데이터가 여러 번 추출될 수도 있고, 어떤 데이터는 한 번도 추출되지 않을 수 있다.
#부스팅(boosting)
(1) 부스팅(boosting)의 개념 및 특징
- 예측력이 약한 모형들을 결함하여 강한 예측 모형을 만드는 방법
- 훈련오차를 빠르고 쉽게 줄임
- 성능이 배깅보다 뛰어난 경우가 많음
- 배깅과 유사하나 붓스트랩 표본을 구성하는 재표본 과정에서 각 자료에 동일한 확률을 부여하지 않고, 분류가 잘못된 데이터에 더 큰 가중을 두어 표본을 추출
- 붓스트랩 표본을 추출해 분류기 생성 → 각 데이터의 확률 조정 → 다음 붓스트랩 표본 추출 → 분류기 생성 → ···
#부스팅 계열 알고리즘
(1) GBM(Gradient Boosting Algorithm)
- 예측모형의 앙상블 방법론 중 부스팅 계열에 속하는 알고리즘.
- 회귀분석 또는 분류 분석을 수행할 수 있는 예측모형
- Gradient Boosting Algorithm을 구현한 패키지: LightGBM, CatBoost, XGBoost 등
(2) LGBM(Light GBM, Light Gradient Boosting) ★
- LGBM은 GBM의 한 종류
- 예측모형의 앙상블 방법론 중 부스팅 계열에 속하는 알고리즘
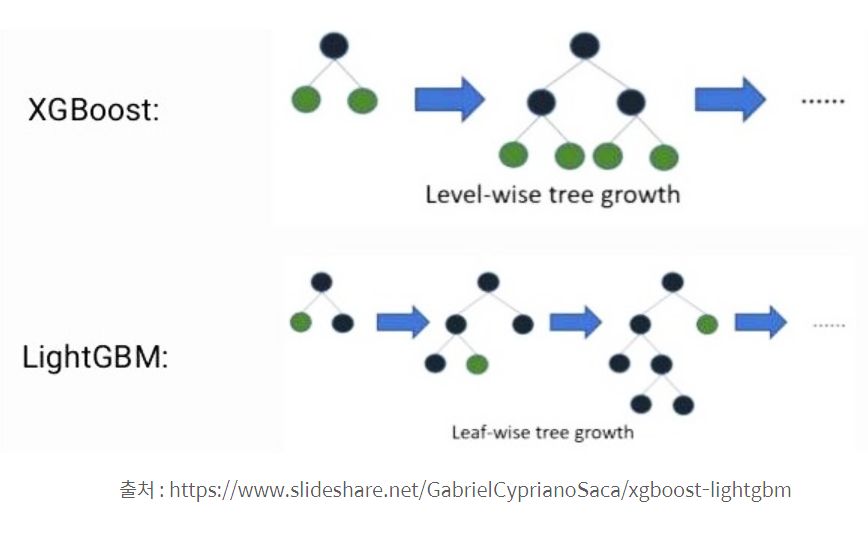
- 일반적인 GBM 패키지와 다르게 LGBM은 leaf wise(리프 중심 트리 분할)방식을 사용한다.
- LGBM은 균형적으로 트리를 분할하지 않는 대신 최대 손실값(max delta loss)을 갖는 트리 노드를 계속 분할
(3) XGBoost vs. LGBM
| XGBoost | LGBM |
| - XGboost는 학습 시간이 오래 걸린다. - Grid search를 통해 최적의 파라미터를 탐색한다면 학습 시간의 효율을 고려해야 한다. |
- LGBM은 XGBoost보다 학습 시간이 덜 걸리며 메모리 사용도 작다는 장점이 있다. - LGBM은 데이터셋의 과적합을 조심해야 하는데, 1만개 이하의 데이터셋은 과적합 위험이 있다. |
#랜덤포레스트(random forest)
- 배깅에 랜덤 과정을 추가한 방법
- 분삭이 큰 의사결정나무를 고려하여 배깅과 부스팅보다 더 많은 무작위성을 주어 약한 학습기들을 생성 후 이를 선형 결함하여 최종 학습기를 만드는 방법
- 붓스트랩 샘플을 추출하고 트리를 만들어가는 과정은 배깅과 유사
- 예측변수들을 임의로 추출하고, 추출된 변수 내에서 최적의 분할을 만들어나감
(배깅 : 각 노드마다 모든 예측변수 안에서 최적의 분할을 선택)
- 변수 제거 없이 실행되어 정확도가 좋음
- 해석이 어렵지만 예측력이 높음 (입력 변수가 많을구록 배깅, 부스팅보다 좋음)
- 별도의 검증용 데이터를 사용하지 않더라도, 붓스트랩 샘플과정에서 제외된 자료를 통해 검증을 실시할 수 있다.
- Category 변수의 value 종류가 32개까지됨
- randomForest 패키지, 랜덤한 forest에 많은 트리 생성
(참고 사이트)
https://logoflife.tistory.com/28
https://kim-mj.tistory.com/144
https://github.com/hw79chopin/Project_Kaggle_Card_fraud_detection
'Certificates > ADsP' 카테고리의 다른 글
| [ADsP] 회귀분석 (0) | 2020.08.12 |
|---|---|
| [ADsP] 분류 모형 평가 (0) | 2020.08.10 |
| [ADsP] 신경망 모형 (0) | 2020.08.07 |
| [ADsP] 데이터 마이닝 개요 (0) | 2020.08.06 |
| [ADsP] 분류 분석 - 로지스틱 회귀모형 (0) | 2020.08.06 |




댓글