1. 데이터 이해
1-1. 데이터의 이해
1-2. 데이터의 가치와 미래
1-3. 가치 창조를 위한 데이터 사이언스와 전략 인사이트
2. 데이터 분석 기획
2-1. 데이터 분석 기획의 이해
2-2. 분석 마스터 플랜
3. 데이터 분석
3-1. R 기초와 데이터 마트
3-2. 통계분석
3-3. 정형 데이터 마이닝
3-3-1. 데이터 마이닝 개요
3-3-2. 분류 분석
3-3-3. 군집 분석
3-3-4. 연관 분석
분류 분석
로지스틱 회귀모형
신경망 모형
의사결정나무 모형
앙상블 모형
분류 모형 평가
- 데이터의 실체가 어떤 그룹에 속하는지 예측하는데 사용되는 기법
- 분류 모델링: 신용 평가 모형(우량, 불량), 사기방지모형(사기, 정상), 이탈모형(이탈, 유지)
- 분류 vs 예측
| 구분 | 분류 | 예측 |
| 공통점 | 레코드의 특정 속성의 값을 미리 알아 맞힘 | |
| 차이점 | 레코드의 범주형 속성 값을 맞힘 | 레코드의 연속형 속성 값을 맞힘 |
| 예시 | 학생의 내신 등급 1년 후 신용등급 |
수능 점수 연 매출액 |
신경망 모형
#신경망 모형의 정의 및 특징
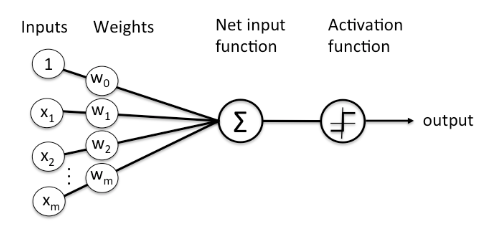
- 동물의 뇌신경계를 모방하여 분류 또는 예측을 위해 만들어진 모형
- 가중치 W=(W1, ···, Wd)'는 의사결정 경계의 방향을 나타내는 모수
- 편의 W0는 의사결정 경계의 위치를 결정하는 모수
- 가중치와 편의는 학습을 통해 오차제곱합이 최소가 되는 방향으로 갱신된다.
| 장점 | 단점 |
|
- 변수의 수가 많거나, 입ㆍ출력 변수 간에 복잡한 비선형 관계가 존재할 때 유용 |
- 결과에 대한 해석이 쉽지 않음 |
#인공신경망
- 인간 뇌를 기반으로 한 추론 모델
- 뉴런은 기본적인 정보처리 단위
- 뉴런은 가중치가 있는 링크들로 연결
- 뉴런은 여러 입력 신호를 받지만 출력 신호는 오직 하나만 생성
#인공신경망의 학습
- 가중치를 반복적으로 조정하여 학습
- 뉴런은 링크로 연결되어 있고, 각 링크에는 수치적인 가중치
- 가중치 조정 방식: 초기화 후, 훈련 데이터를 통해 갱신, 신경망의 구조를 선택 후 활용할 학습 알고리즘 결정한 후 신경망 훈련
#신경망 모형 구축 시 고려사항
1) 입력 변수
- 복잡성에 의하여 입력 자료 선택에 민감
- 범주형 변수: 모든 범주에서 일정 빈도 이상, 빈도 일정
- 범주형 변수의 경우, 모든 범주형 변수가 같은 범위를 갖도록 가변수화 해야 함.
- 연속형 변수: 입력 변수들의 범위가 변수간 큰 차이가 없을 때
- 연속형 변수의 경우, 분포가 평균 중김으로 대칭이야 함
2) 가중치의 초기값과 다중 최소값 문제
- 초기값 선택 중요
- 가중치가 0이면, 신경망 모형은 근사적 선형 모형
- 초기값은 0근처로 랜덤하게 선택, 가중치가 증가할 수록 비선형
3) 학습모드
- 온라인 학습모드: 관측값을 순차적으로 투입하여 가중치 추정값이 매번 바뀜(속도 빠름, 훈련 자료가 비정상성일 때 좋음, 국소 최소값에 벗어나기 쉬움)
- 확률적 학습모드: 관측값을 랜덤하게 투입하여 가중치 추정값이 매번 바뀜
- 배치 학습모드: 전체 훈련자료를 동시에 투임
4) 은닉층과 은닉 노드의 수
- 신경망 적용 시 제일 중요한 부분: 모형 선택(은닉층, 은닉노드의 수 결정)
- 많으면 가중치가 많아져 과대 적합 문제 발생
- 은닉층 구 결정: 하나로 선정
- 은닉노드 수 결정: 적절히 큰 값을 놓고 가중치 감소시키면서 적용
5) 과대 적합 문제
- 알고리즘 조기 종료와 가중치 감소 기법으로 해결
- 조기 종료: 검증 오차가 증가하기 시작하면 반복 중지
- 가중치 감소라는 벌점화 기법 활용
(참고 사이트)
'Certificates > ADsP' 카테고리의 다른 글
| [ADsP] 분류 모형 평가 (0) | 2020.08.10 |
|---|---|
| [ADsP] 앙상블 모형 (0) | 2020.08.07 |
| [ADsP] 데이터 마이닝 개요 (0) | 2020.08.06 |
| [ADsP] 분류 분석 - 로지스틱 회귀모형 (0) | 2020.08.06 |
| [ADsP] 군집 분석 - SOM (Self-Organizing Maps, 자기조직화지도) (0) | 2020.08.03 |




댓글