이전 글에서 언급했듯이 이번 글에서는 '신경망 첫걸음(타리트 라시드)'의 MNIST 손글씨 데이터 인식하기 실습을 수행하고자 한다. 먼저 데이터셋을 다운 받아야 하는데 경로는 적절히 선택하면 되겠다.
제공되는 Dataset와 Code
- MNIST train data: http://www.pjreddie.com/media/files/mnist_train.csv
- MNIST test data: http://www.pjreddie.com/media/files/mnist_test.csv
- MNIST train data (100개): https://git.io/vySZ1
- MNIST test data (10개): https://git.io/vySZP
- part2_neural_network_mnist_data.ipynb
아래는 실습을 위해 작성한 COLAB 링크이며, 각 코드를 실행하기 위해서는 Files 경로에 위의 4개의 데이터 파일을 업로드해야한다.
MNIST 데이터 불러오기
- open(): open()의 매개 변수는 2개이나 "경로/파일명"만 넣어도 된다.
- .readlines(): 파일의 모든 행을 읽어서 data_list하는 변수에 저장한다.
- 각 행이 한 리스트의 원소가 된다.
- 전체 파일을 읽으므로 데이터가 작을 때만 사용하는 것이 좋다.
- .close(): 한 번 연 파일은 닫아주는 것이 좋다.
#데이터를 불러오고 그 파일을 읽는다.
data_file = open("mnist_train_100.csv",'r') #'r'은 읽기 전용
data_list = data_file.readlines()
data_file.close()
리스트의 길이가 100이며, 첫 번째 원소를 확인했을 때 5로 시작하는 것을 알 수 있다. 이는 첫 번째 숫자가 5일 경우 이미지의 레이블은 5라는 것을 알 수 있다.

배열의 이용과 시각화를 도와줄 라이브러리를 불러온다.
import numpy
import matplotlib.pyplot
%matplotlib inlineimshow() 함수를 이용해 행렬을 시각화하기 위해 쉼표로 구분된 숫자들의 리스트를 적절한 행렬로 변환해줘야 한다.
- 구분자로 쉼표를 이용해 긴 텍스트 문자열을 개별 값으로 분리한다.
- 레이블 값인 첫 번째 값은 무시하고 나머지 28X28 = 784의 값을 추출한 후, 이를 28개의 행과 28개의 열의 형태를 가지는 배열로 변환다.
all_values = data_list[0].split(',')
image_array = numpy.asfarray(all_values[1:]).reshape((28,28))
matplotlib.pyplot.imshow(image_array, cmap='Greys', interpolation='None') - split(): 구분자로 사용할 기호를 그 매개변수로 가진다. 리스트를 불러와서 쉼표로 구분하여 분리한다.
- numpy.asfarray(): 문자열을 실수로 변환한 다음에 그 숫자로 구성된 배열을 생성한다.
- reshape((28,28)): 784개의 어레이 숫자들을 28 x 28 형태의 정방 행렬로 만들어 준다
- all_values[1:]: 리스트의 원소중 가장 첫 번째 원소는 이 원소들이 무엇을 표현하는 것인지를 알려주는 것이기 때문에 빼준다.
- imshow(): image_array를 회색으로 시각화한다.
data_list[0]일 경우 5를 시각화화며, data_list[1]일 경우 0을 시각화한다.

NMIST 학습 데이터 준비하기
신경망의 학습단계와 질의 단계에 적용하기 위해 데이터 값의 범위를 재조정함으로써 준비해야 한다. 입력 데이터와 출력 데이터의 값들이 적절한 형태를 가져야 활성화 함수의 수용 번위 내에 있게 되어 신경망은 더 잘 작동이 된다.
# scale input to range 0.01 to 1.00
scaled_input = (numpy.asfarray(all_values[1:]) / 255.0 * 0.99) + 0.01
print(scaled_input)0~255 사이의 입력 색상 값들의 범위를 0.01~1.0 사이에 속하도록 조정한다. 255개로 값들을 나눈 뒤 0.99를 곱하고 +0.01을 함으로써 하한선은 0.01 상한선은 1.0로 한다.

여기서 신경망에 바라는 점을 생각해본다면, 이미지를 분류해 정확한 레이블(0~9, 10개)을 할당하는 것이다. 그래서 만약 5(6번째 원소)에 상응하는 노드 외에는 작은 값을 가지도록 행렬을 구성한다면 [0,0,0,0,0,1,0,0,0,0]로 구성할 수 있다.
그러나 활성화 함수가 도달할 수 없는 0과 1이라는 값을 사용하게 되면 큰 값의 가중치로 인해 신경망이 포화될 수 있기 때문에 0.01~0.99 범위를 적용하고자 한다.
#출력 노드 계층의 노드 수는 10 (10개의 레이블)
onodes = 10
targets = numpy.zeros(onodes) + 0.01 #0을 피하기 위해 +0.01
targets[int(all_values[0])] = 0.99
print(targets)- numpy.zeros(): 0으로 채워진 행렬 생성, 매개 변수는 행렬의 크기와 형태 (노드의 수 = 10)
- int(): targets[9]처럼 인덱스는 정수로 표현해야 하기 때문에 int() 함수 사용
레이블 (all_values[0])한 숫자를 0.99로 설정하면 아래와 같이 결과가 나온다.

이제 저번 글에서 작성했던 신경망 파이썬 코드를 업데이트 하보자.
#3계층의 신경망으로 MNIST 데이터를 학습하는 코드
import numpy
# 시그모이드 함수 expit() 사용을 위해 scipy.special 불러오기
import scipy.special
# 행렬을 시각화하기 위한 라이브러리
import matplotlib.pyplot
# 시각화가 외부 윈도우가 아닌 현재의 노트북 내에서 보이도록 설정
%matplotlib inline# 신경망 클래스의 정의
class neuralNetwork:
# 신경망 초기화하기
def __init__(self, inputnodes, hiddennodes, outputnodes, learningrate):
# 입력, 은익, 출력 계층의 노드 개수 설정
self.inodes = inputnodes
self.hnodes = hiddennodes
self.onodes = outputnodes
# 가중치 matrices, wih와 who
# arrays 내 가중치는 w_i_j로 표기
self.wih = numpy.random.normal(0.0, pow(self.hnodes, -0.5), (self.hnodes, self.inodes))
self.who = numpy.random.normal(0.0, pow(self.onodes, -0.5), (self.onodes, self.hnodes))
# 학습률
self.lr = learningrate
# activation 함수는 sigmoid 함수
self.activation_function = lambda x: scipy.special.expit(x)
pass
# 신경망 학습시키기
def train(self, inputs_list, targets_list):
# 입력 리스트를 2차원의 행렬로 변환
inputs = numpy.array(inputs_list, ndmin=2).T
targets = numpy.array(targets_list, ndmin=2).T
# 은닉 계층으로 들어오는 신호를 계산
hidden_inputs = numpy.dot(self.wih, inputs)
# 은닉 계층에서 나가는 신호를 계산
hidden_outputs = self.activation_function(hidden_inputs)
# 최종 출력 계층으로 들어오는 신호를 계산
final_inputs = numpy.dot(self.who, hidden_outputs)
# 최종 출력 계층에서 나가는 신호를 계산
final_outputs = self.activation_function(final_inputs)
# 출력 계층의 오차는 (target - actual)
output_errors = targets - final_outputs
# 은닉 계층의 오차는 가중치에 의해 나뉜 출력 계층의 오차들을 재조합해 계산
hidden_errors = numpy.dot(self.who.T, output_errors)
# 은닉 계층과 출력 계층 간의 가중치 업데이트
self.who += self.lr * numpy.dot((output_errors * final_outputs * (1.0 - final_outputs)), numpy.transpose(hidden_outputs))
# 입력 계층과 은닉 계층 간의 가중치 업데이트
self.wih += self.lr * numpy.dot((hidden_errors * hidden_outputs * (1.0 - hidden_outputs)), numpy.transpose(inputs))
pass
# 신경망에 질의하기
def query(self, inputs_list):
# inputs list를 2d array로 변환
inputs = numpy.array(inputs_list, ndmin=2).T
# hidden layer로 들어오는 신호 계산
hidden_inputs = numpy.dot(self.wih, inputs)
# hidden layer에서 나가는 신호 계산
hidden_outputs = self.activation_function(hidden_inputs)
# final output layer로 들어오는 신호 계산
final_inputs = numpy.dot(self.who, hidden_outputs)
# final output layer에서 나가는 신호 계산
final_outputs = self.activation_function(final_inputs)
return final_outputs# input, hidden, output 노드 수
input_nodes = 784
hidden_nodes = 100
output_nodes = 10
# learning rate는 0.3
learning_rate = 0.3
# instance of neural network 생성
n = neuralNetwork(input_nodes,hidden_nodes,output_nodes, learning_rate)- 입력 노드 수: 손글씨 숫자 이미지를 구성하는 픽셀이 28x28의 크기를 가지기 때문에 784개로 설정
- 은닉 노드 수: 노드 수 설정의 과학적 근거는 없다.
- 입력 값의 수보다 작은 형태의 패턴을 찾기 때문에 784개보다 작은 값
- 출력 노드가 10개이므로 100개라는 임의의 값 설정
- 출력 노드의 수: 0~9라는 10개의 레이블로 구분
이제 100개의 레코드를 가진 toy data를 불러와서 학습을 시켜보자.
# toy 학습 데이터 불러오기
data_file = open("mnist_train_100.csv", 'r')
data_list = data_file.readlines()
data_file.close()# neural network 학습 시키기
# 학습 데이터 모음 내의 모든 레코드 검색
for record in data_list:
# ',' 에 의해 분리
all_values = record.split(',')
# 입력 값의 범위와 값 조정
inputs = (numpy.asfarray(all_values[1:]) / 255.0 * 0.99) + 0.01
# target output values 생성 (desired label은 0.99, 그 이외에는 0.01 처리)
targets = numpy.zeros(output_nodes) + 0.01
# all_values[0]은 이 record의 target label
targets[int(all_values[0])] = 0.99
n.train(inputs, targets)
pass
신경망 테스트하기
10개의 레코드로 테스트를 하고자 "mnist_test_10.csv"라는 test data를 불러온다.
# mnist test data CSV 파일은 list로 불러오기
test_data_file = open("mnist_test_10.csv", 'r')
test_data_list = test_data_file.readlines()
test_data_file.close()이 데이터의 첫 번째 record의 label은 7이며, 이를 시각화 했을 때도 7임을 알 수 있다.
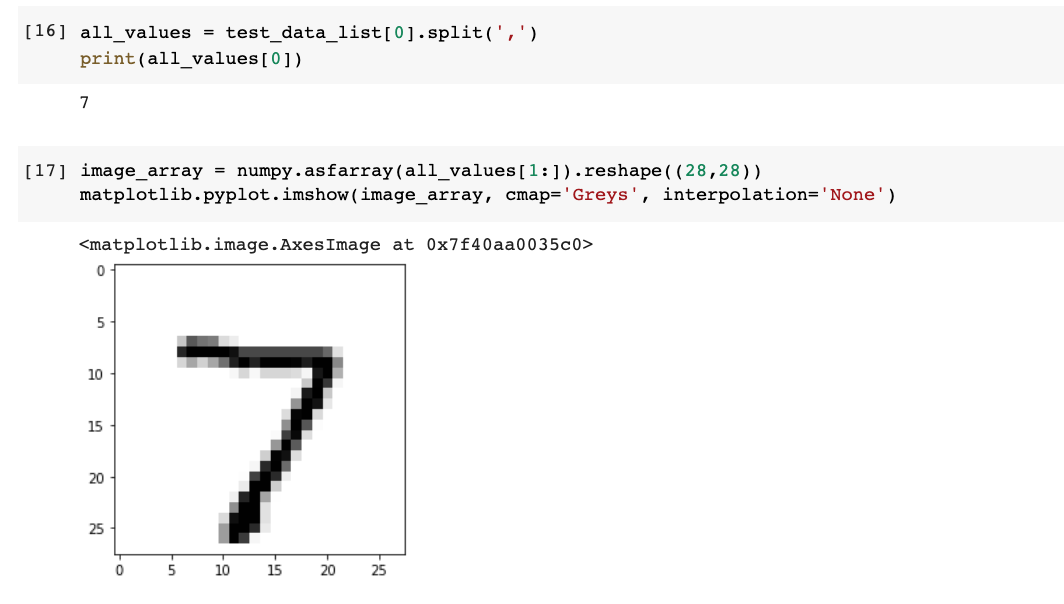
n.query((numpy.asfarray(all_values[1:]) / 255.0 * 0.99) + 0.01)위와 같이 n.query()를 활용해 신경망에 질의해봤을 때
8번째 원소인 7의 값이 가장 크므로 잘 작동하는 것을 확인할 수 있다.

전체 데이터를 이용해 학습 및 테스트하기
이제 파일명을 전체 데이터로 바꾸고, 전체 데이터를 적용해보자.
#3계층의 신경망으로 MNIST 데이터를 학습하는 코드
import numpy
# 시그모이드 함수 expit() 사용을 위해 scipy.special 불러오기
import scipy.special
# 행렬을 시각화하기 위한 라이브러리
import matplotlib.pyplot
# 시각화가 외부 윈도우가 아닌 현재의 노트북 내에서 보이도록 설정
%matplotlib inline
# 신경망 클래스의 정의
class neuralNetwork:
# 신경망 초기화하기
def __init__(self, inputnodes, hiddennodes, outputnodes, learningrate):
# 입력, 은익, 출력 계층의 노드 개수 설정
self.inodes = inputnodes
self.hnodes = hiddennodes
self.onodes = outputnodes
# 가중치 matrices, wih와 who
# arrays 내 가중치는 w_i_j로 표기
self.wih = numpy.random.normal(0.0, pow(self.hnodes, -0.5), (self.hnodes, self.inodes))
self.who = numpy.random.normal(0.0, pow(self.onodes, -0.5), (self.onodes, self.hnodes))
# 학습률
self.lr = learningrate
# activation 함수는 sigmoid 함수
self.activation_function = lambda x: scipy.special.expit(x)
pass
# 신경망 학습시키기
def train(self, inputs_list, targets_list):
# 입력 리스트를 2차원의 행렬로 변환
inputs = numpy.array(inputs_list, ndmin=2).T
targets = numpy.array(targets_list, ndmin=2).T
# 은닉 계층으로 들어오는 신호를 계산
hidden_inputs = numpy.dot(self.wih, inputs)
# 은닉 계층에서 나가는 신호를 계산
hidden_outputs = self.activation_function(hidden_inputs)
# 최종 출력 계층으로 들어오는 신호를 계산
final_inputs = numpy.dot(self.who, hidden_outputs)
# 최종 출력 계층에서 나가는 신호를 계산
final_outputs = self.activation_function(final_inputs)
# 출력 계층의 오차는 (target - actual)
output_errors = targets - final_outputs
# 은닉 계층의 오차는 가중치에 의해 나뉜 출력 계층의 오차들을 재조합해 계산
hidden_errors = numpy.dot(self.who.T, output_errors)
# 은닉 계층과 출력 계층 간의 가중치 업데이트
self.who += self.lr * numpy.dot((output_errors * final_outputs * (1.0 - final_outputs)), numpy.transpose(hidden_outputs))
# 입력 계층과 은닉 계층 간의 가중치 업데이트
self.wih += self.lr * numpy.dot((hidden_errors * hidden_outputs * (1.0 - hidden_outputs)), numpy.transpose(inputs))
pass
# 신경망에 질의하기
def query(self, inputs_list):
# inputs list를 2d array로 변환
inputs = numpy.array(inputs_list, ndmin=2).T
# hidden layer로 들어오는 신호 계산
hidden_inputs = numpy.dot(self.wih, inputs)
# hidden layer에서 나가는 신호 계산
hidden_outputs = self.activation_function(hidden_inputs)
# final output layer로 들어오는 신호 계산
final_inputs = numpy.dot(self.who, hidden_outputs)
# final output layer에서 나가는 신호 계산
final_outputs = self.activation_function(final_inputs)
return final_outputs
# input, hidden, output 노드 수
input_nodes = 784
hidden_nodes = 100
output_nodes = 10
# learning rate는 0.3
learning_rate = 0.3
# instance of neural network 생성
n = neuralNetwork(input_nodes,hidden_nodes,output_nodes, learning_rate)# 60,000개의 레코드를 가지는 전체 학습 데이터 불러오기
training_data_file = open("mnist_train.csv", 'r')
training_data_list = training_data_file.readlines()
training_data_file.close()# neural network 학습 시키기
# 학습 데이터 모음 내의 모든 레코드 검색
for record in data_list:
# ',' 에 의해 분리
all_values = record.split(',')
# 입력 값의 범위와 값 조정
inputs = (numpy.asfarray(all_values[1:]) / 255.0 * 0.99) + 0.01
# target output values 생성 (desired label은 0.99, 그 이외에는 0.01 처리)
targets = numpy.zeros(output_nodes) + 0.01
# all_values[0]은 이 record의 target label
targets[int(all_values[0])] = 0.99
n.train(inputs, targets)
pass# 10,000개의 레코드를 가지는 전체 테스트 데이터 불러오기
test_data_file = open("mnist_test.csv", 'r')
test_data_list = test_data_file.readlines()
test_data_file.close()
신경망 테스트를 가지고 신경망의 성능 지표가 되는 성적표를 만들고, 정답의 비율을 출력하는 코드를 작성해 보자.
반복문에서 각 레코드를 돌 때마다 scorecard 리스트를 업데이트할 것이다. 그리고 첫 번째 값을 정답 라벨(correct_label)로 정의한다.
그리고 가장 큰 값을 가지는 출력 노드가 신경망이 생각하는 답이고, 그 노드의 인덱스가 레이블과 일치하며 만약 그 레이블이 정답 라벨일 경우 1을 추가하고 오답을 경우 0을 추가한다.
- numpy.argmax(): 행렬 내 가장 큰 값을 찾아 위치를 알려줌
# neural network 테스트
# 신경망의 성능 지표가 되는 성적표 초기화
scorecard = []
# test data 모음 내의 모든 record 탐색
for record in test_data_list:
# ',' 에 의해 분리
all_values = record.split(',')
# 정답은 첫 번째 값
correct_label = int(all_values[0])
# 입력 값의 범위와 값 조정
inputs = (numpy.asfarray(all_values[1:]) / 255.0 * 0.99) + 0.01
# 신경망에 질의 후 응답을 outputs 변수에 저장
outputs = n.query(inputs)
# 가장 높은 값의 인덱스는 레이블의 인덱스와 일치
label = numpy.argmax(outputs)
# 정답 또는 오답을 리스트에 추가
if (label == correct_label):
# 정답인 경우 성적표에 1을 더함
scorecard.append(1)
else:
# 정답이 아닌 경우 성적표에 0을 더함
scorecard.append(0)
pass
pass
성적표를 만들었으면 이 성적표에서의 정답 비율을 계산해 'performace' 값을 출력해보자. scorecard를 실수의 array로 바꾸어 주고, 이 scorecard array 내 값을 모두 더한 다음 scorecard array의 크기로 나눠주면 정답의 비율 즉 정확도을 출력한다.
# 정답의 비율인 성적을 계산해 출력
scorecard_array = numpy.asarray(scorecard)
print ("performance = ", scorecard_array.sum() / scorecard_array.size)
학습률, 주기, 은닉 노드 수 변경을 통한 신경망의 개선
위 첫 번째 신경망에서 93.75%라는 정확도를 달성했지만 학습률, 주기(epoch), 은닉 노드 수를 변경하는 실험을 통해 더 나은 성능의 조건이 있는지 알아볼 수 있다.
- 주기(epoch): 학습 데이터가 학습을 위해 사용되는 횟수, 너무 많이 학습하면 과적합(overfitting) 발생
은닉 노드의 경우 너무 적으면 학습할 공간이 없어진다. 직관적으로 이해가 어렵지만 이 책에서는 예를 들어 3개의 은닉노드일 경우 3개의 좌석을 가진 자동차에 10명을 태우는 걸 상상하면 된다고 설명한다. 그렇다고 은닉 노드 수가 너무 많으면 선택지가 많아 신경망 학습이 어렵다고 한다.
최적의 학습률, 주기, 은닉 노드 수로 변경한 뒤 다시 학습 및 테스트를 진행해 보겠다.
- hidden_nodes: 100에서 200로 변경
- learning_rate: 0.3에서 0.2로 변경
- epoch: 7로 설정
input_nodes = 784
hidden_nodes = 200
output_nodes = 10
learning_rate = 0.2
n = neuralNetwork(input_nodes,hidden_nodes,output_nodes, learning_rate)training_data_file = open("mnist_train.csv", 'r')
training_data_list = training_data_file.readlines()
training_data_file.close()# 학습
# 주기(epoch): 학습 데이터가 학습을 위해 사용되는 횟수
epochs = 7
for e in range(epochs):
for record in training_data_list:
all_values = record.split(',')
inputs = (numpy.asfarray(all_values[1:]) / 255.0 * 0.99) + 0.01
targets = numpy.zeros(output_nodes) + 0.01
targets[int(all_values[0])] = 0.99
n.train(inputs, targets)
pass
passtest_data_file = open("mnist_test.csv", 'r')
test_data_list = test_data_file.readlines()
test_data_file.close()scorecard = []
for record in test_data_list:
all_values = record.split(',')
correct_label = int(all_values[0])
inputs = (numpy.asfarray(all_values[1:]) / 255.0 * 0.99) + 0.01
outputs = n.query(inputs)
label = numpy.argmax(outputs)
if (label == correct_label):
scorecard.append(1)
else:
scorecard.append(0)
pass
passscorecard_array = numpy.asarray(scorecard)
print ("performance = ", scorecard_array.sum() / scorecard_array.size)
최종적으로 93.75%에서 97.09%로 정확도가 높아진 것을 확인할 수 있다.
시간이 허락한다면 내 손글씨를 이용해 신경망에 적용해보는 실습 내용을 포스팅하겠다. 해당 실습의 저자가 작성한 github 내 코드는 아래와 같다.
'Studies & Courses > Machine Learning & Vision' 카테고리의 다른 글
| [ML/DL] 수포자가 이해한 Cross Entropy와 KL-divergence (0) | 2021.01.08 |
|---|---|
| [ML/DL] 수포자가 이해한 2-Layer Neural Net의 vector form (0) | 2021.01.05 |
| [ML/DL] 파이썬으로 인공 신경망 만들기 (1) | 2020.12.29 |
| [ML 기초] 수포자가 이해한 미분과 편미분 (feat. 경사하강법) (0) | 2020.12.05 |
| [머신러닝 기초] NumPy Tutorial - Python (0) | 2020.10.24 |




댓글