이번 실험에서는 pre-trained COCO checkpoint를 받아온 뒤 RetinaNet architecture의 TF2에 맞게 fine tuning을 하여 example에 적용해보도록 하겠습니다. 이 실험은 Colab에서 구현했으며 GPU를 사용하면 5분 이하로 걸릴 것입니다.
Imports
먼저 tensorflow를 설치합니다.
!pip install -U --pre tensorflow=="2.2.0"Tensorflow Object Detection API를 다운로드합니다.
import os
import pathlib
#tensorflow model repository를 clone하기
if "models" in pathlib.Path.cwd().parts:
while "models" in pathlib.Path.cwd().parts:
os.chdir('..')
elif not pathlib.Path('models').exists():
!git clone --depth 1 https://github.com/tensorflow/models\models\research 디렉토리로 이동하여 다음의 명령어를 실행해 install 합니다. 여기서 %%bash는 뒤의 코드는 bash로 execute된다는 의미입니다.
# Object Detection API 설치하기
%%bash
cd models/research/
protoc object_detection/protos/*.proto --python_out=.
cp object_detection/packages/tf2/setup.py .
python -m pip install.각종 모듈을을 import 합니다.
import matplotlib
import matplotlib.pyplot as plt
import os
import random
import io
import imageio
import glob
import scipy.misc
import numpy as np
from six import BytesIO
from PIL import Image, ImageDraw, ImageFont
from IPython.display import display, Javascript
from IPython.display import Image as IPyImage
import tensorflow as tf
from object_detection.utils import label_map_util
from object_detection.utils import config_util
from object_detection.utils import visualization_utils as viz_utils
from object_detection.utils import colab_utils
from object_detection.builders import model_builder
%matplotlib inlineUtilities
def load_image_into_numpy_array(path):
img_data = tf.io.gfile.GFile(path, 'rb').read()
image = Image.open(BytesIO(img_data))
(im_width, im_height) = image.size
return np.array(image.getdata()).reshape(
(im_height, im_width, 3)).astype(np.uint8)
plot_detection
Detection을 visualize하기 위해 wrapper function을 정의합니다.
Args:
image_np: shape (img_height, img_width, 3)의 uint8 numpy array
boxes: shape [N, 4]의 numpy array
classes: shape [N]의 numpy array
class index는 1-based이며, label map에 있는 key와 match됩니다.
scores: shape[N]의 numpy array
만약 scores=None일 때 이 function은 plot되는 box가 groundtruth boxes인지 예측하고 class나 score가 없는 box는 모든 box를 black으로 plot합니다.
category_index: category dictionary를 담은 dictionary이며, category index는 id이고, category name은 name입니다.
figsize: figure를 위한 사이즈
image_name: 이미지 파일명
def plot_detections(image_np,
boxes,
classes,
scores,
category_index,
figsize=(12, 16),
image_name=None):
image_np_with_annotations = image_np.copy()
viz_utils.visualize_boxes_and_labels_on_image_array(
image_np_with_annotations,
boxes,
classes,
scores,
category_index,
use_normalized_coordinates=True,
min_score_thresh=0.8)
if image_name:
plt.imsave(image_name, image_np_with_annotations)
else:
plt.imshow(image_np_with_annotations)
Rubber Ducky data
5개의 Rubber Ducky 이미지를 가져와서 시각화합니다.
# 이미지 가져와서 시각화 하기
train_image_dir = 'models/research/object_detection/test_images/ducky/train/'
train_images_np = []
for i in range(1, 6):
image_path = os.path.join(train_image_dir, 'robertducky' + str(i) + '.jpg')
train_images_np.append(load_image_into_numpy_array(image_path))
plt.rcParams['axes.grid'] = False
plt.rcParams['xtick.labelsize'] = False
plt.rcParams['ytick.labelsize'] = False
plt.rcParams['xtick.top'] = False
plt.rcParams['xtick.bottom'] = False
plt.rcParams['ytick.left'] = False
plt.rcParams['ytick.right'] = False
plt.rcParams['figure.figsize'] = [14, 7]
for idx, train_image_np in enumerate(train_images_np):
plt.subplot(2, 3, idx+1)
plt.imshow(train_image_np)
plt.show()
이미지에 bounding box를 annotation하기
rubber duckies image 내 next image 를 box를 그린 뒤 더이상 이미지 없으면 submit 버튼을 누릅니다. 사전에 pre-annotated bounding boxes로 groundtruth를 prepopulation해놓은 다음 cell에서 진행해도 되니 skip하셔도 됩니다.
gt_boxes = []
colab_utils.annotate(train_images_np, box_storage_pointer=gt_boxes)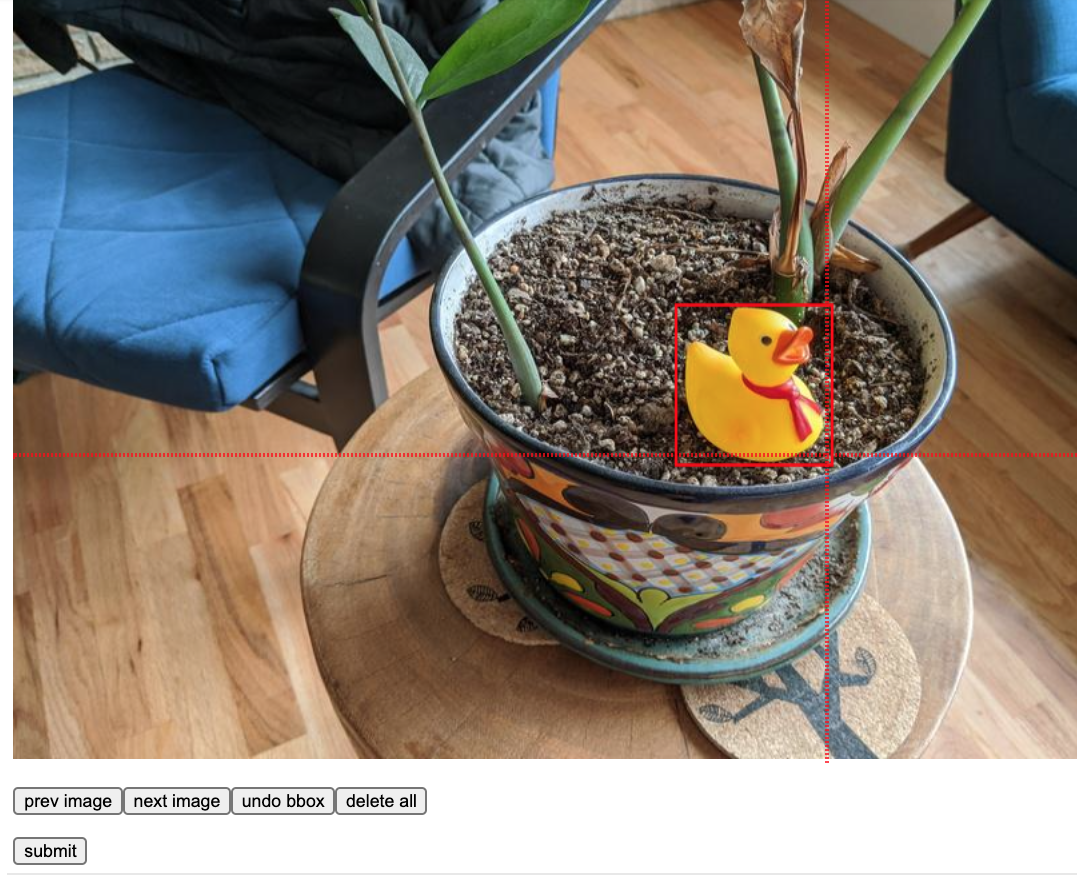
라벨링을 원하지 않는 경우
아래 코드를 사용해 같이 사전에 annotate된 박스를 사용할 수 있습니다.
gt_boxes = [
np.array([[0.436, 0.591, 0.629, 0.712]], dtype=np.float32),
np.array([[0.539, 0.583, 0.73, 0.71]], dtype=np.float32),
np.array([[0.464, 0.414, 0.626, 0.548]], dtype=np.float32),
np.array([[0.313, 0.308, 0.648, 0.526]], dtype=np.float32),
np.array([[0.256, 0.444, 0.484, 0.629]], dtype=np.float32)
]학습을 위한 데이터 준비
class annotations을 추가합니다. (multiple classes를 다룰 수 있도록 확장되어야 하지만 이 이 실험에서는 간단하게 진행하기 위해 single class만 추측합니다.) 우리는 모든 것을 아래 training loop가 잘 돌 수 있는 fromat으로 변환합니다. (예: class를 one-hot representations 변환)
# convention에 따르면, background가 없는 class의 경우 1부터 세기 시작합니다.
# 이는 하나의 클래스만 예측하며 'class id' 1로 할당합니다.
duck_class_id = 1
num_classes = 1
category_index = {duck_class_id: {'id': duck_class_id, 'name': 'rubber_ducky'}}
# class label을 one-hot으로 변환하고, 모든 것을 tensor로 바꿉니다.
# 'label_id_offset'은 모든 class를 index 번호대로 바꿉니다.
# 이는 모델이 non-background classes 0번째 index에서 카운팅되는 one-hot label을 받게 하기 위함입니다.
# 이는 원래 자동적으로 training binary 내에서 다뤄지지만 여기서는 다시 만들 필요가 있습니다.
label_id_offset = 1
train_image_tensors = []
gt_classes_one_hot_tensors = []
gt_box_tensors = []
for (train_image_np, gt_box_np) in zip(
train_images_np, gt_boxes):
train_image_tensors.append(tf.expand_dims(tf.convert_to_tensor(
train_image_np, dtype=tf.float32), axis=0))
gt_box_tensors.append(tf.convert_to_tensor(gt_box_np, dtype=tf.float32))
zero_indexed_groundtruth_classes = tf.convert_to_tensor(
np.ones(shape=[gt_box_np.shape[0]], dtype=np.int32) - label_id_offset)
gt_classes_one_hot_tensors.append(tf.one_hot(
zero_indexed_groundtruth_classes, num_classes))
print('Done prepping data.')Sanity check를 위한 rubber duckies 시각화
box에 100%의 score을 주고, 30x15 사이즈로 rubber duckies를 시각화합니다. Sanity check란 빠르게
# box에 100%의 score을 줍니다.
dummy_scores = np.array([1.0], dtype=np.float32)
plt.figure(figsize=(30, 15))
for idx in range(5):
plt.subplot(2, 3, idx+1)
plot_detections(
train_images_np[idx],
gt_boxes[idx],
np.ones(shape=[gt_boxes[idx].shape[0]], dtype=np.int32),
dummy_scores, category_index)
plt.show()
모델 만든 뒤 마지막 layer를 제외하고 weight 복원하기
이 코드에서는 Single stage detection 구조 (RetinaNet)를 만들고 (자동적으로 랜덤하게 초기화된) 맨 위에 있는 classification layer를 제외하고 모든 layer을 복원합니다. 단순화를 위해 직접 RetinaNet architecture를 hardcording을 했지만 이는 다른 model configuration로 generalize하기는 어렵습니다.
# Checkpoint를 다운로드하고 이것을 models/research/object_detection/test_data/ 경로에 넣습니다.
!wget http://download.tensorflow.org/models/object_detection/tf2/20200711/ssd_resnet50_v1_fpn_640x640_coco17_tpu-8.tar.gz
!tar -xf ssd_resnet50_v1_fpn_640x640_coco17_tpu-8.tar.gz
!mv ssd_resnet50_v1_fpn_640x640_coco17_tpu-8/checkpoint models/research/object_detection/test_data/print('Building model and restoring weights for fine-tuning...', flush=True)
num_classes = 1
pipeline_config = 'models/research/object_detection/configs/tf2/ssd_resnet50_v1_fpn_640x640_coco17_tpu-8.config'
checkpoint_path = 'models/research/object_detection/test_data/checkpoint/ckpt-0'pipeline config를 가져오고 detection model을 만듭니다. 90개의 class slot를 예측하는 COCO 구조로 실행하기 때문에 'num_classes' field를 (새로운 rubber ducky class를 위해) override합니다. (Override 설명)
configs = config_util.get_configs_from_pipeline_file(pipeline_config)
model_config = configs['model']
model_config.ssd.num_classes = num_classes
model_config.ssd.freeze_batchnorm = True
detection_model = model_builder.build(
model_config=model_config, is_training=TrueObject-based checkpoint 복원을 준비합니다. RetinaNet는 하나는 classification을 위한, 하나는 box regression을 위한 2개의 'heads'를 가집니다. box regression head을 복원하지만 처음부터는 classification head로 초기화합니다. 두 head를 복원시키고 싶다면 commenting out하면 됩니다. 여기서 head는 특징맵을 이용하여 classification과 regression 작업을 수행하는 부분입니다.
참고로 Head는 dense prediction과 sparse prediction으로 나눱니다.
Sparse prediction(2-stage): classification과 regression이 분리되어 있습니다. (RCNN계열)
Dense prediction(1-stage): classification과 regression이 통합되어 있습니다. (Yolo, SSD계열)
fake_box_predictor = tf.compat.v2.train.Checkpoint(
_base_tower_layers_for_heads=detection_model._box_predictor._base_tower_layers_for_heads,
# _prediction_heads=detection_model._box_predictor._prediction_heads,
# (i.e., the classification head that we *will not* restore)
_box_prediction_head=detection_model._box_predictor._box_prediction_head,
)
fake_model = tf.compat.v2.train.Checkpoint(
_feature_extractor=detection_model._feature_extractor,
_box_predictor=fake_box_predictor)
ckpt = tf.compat.v2.train.Checkpoint(model=fake_model)
ckpt.restore(checkpoint_path).expect_partial()
변수 생성을 위해 dummy image를 model에 돌립니다.
image, shapes = detection_model.preprocess(tf.zeros([1, 640, 640, 3]))
prediction_dict = detection_model.predict(image, shapes)
_ = detection_model.postprocess(prediction_dict, shapes)
print('Weights restored!')즉시 실행 모드(Eager mode) custom training loop
tf.keras.backend.set_learning_phase(True)Fine-tune을 top layers에 있는 variables 선택합니다.
trainable_variables = detection_model.trainable_variables
to_fine_tune = []
prefixes_to_train = [
'WeightSharedConvolutionalBoxPredictor/WeightSharedConvolutionalBoxHead',
'WeightSharedConvolutionalBoxPredictor/WeightSharedConvolutionalClassHead']
for var in trainable_variables:
if any([var.name.startswith(prefix) for prefix in prefixes_to_train]):
to_fine_tune.append(var)single train step을 위해 forward + backward pass를 setup 한뒤, single training iteration을 돌립니다.
Args:
image_tensors: type tf.float32의 [1, height, width, 3] tensor list입니다.
이 함수로 인해 640x640로 reshape되기 때문에 height와 width는 이미지에 따라 달라질 수 있습니다.
groundtruth_boxes_list:
batch 내 각 이미지를 위해 groundtruth box를 나타내는 type tf.float32의 shape [N_i, 4]의 텐서들의 리스트입니다.
Returns:
Input batch에 대한 total loss 를 표현하는 scalar tensor
# Forward + backward pass 준비
def get_model_train_step_function(model, optimizer, vars_to_fine_tune):
"""training step을 위해 tf.function을 가져옵니다. """
# speed를 위해 tf.function 사용하기
# eager하게 실행하고 싶다면 tf.function decorator를 사용
def train_step_fn(image_tensors,
groundtruth_boxes_list,
groundtruth_classes_list):
shapes = tf.constant(batch_size * [[640, 640, 3]], dtype=tf.int32)
model.provide_groundtruth(
groundtruth_boxes_list=groundtruth_boxes_list,
groundtruth_classes_list=groundtruth_classes_list)
with tf.GradientTape() as tape:
preprocessed_images = tf.concat(
[detection_model.preprocess(image_tensor)[0]
for image_tensor in image_tensors], axis=0)
prediction_dict = model.predict(preprocessed_images, shapes)
losses_dict = model.loss(prediction_dict, shapes)
total_loss = losses_dict['Loss/localization_loss'] + losses_dict['Loss/classification_loss']
gradients = tape.gradient(total_loss, vars_to_fine_tune)
optimizer.apply_gradients(zip(gradients, vars_to_fine_tune))
return total_loss
return train_step_fnoptimizer = tf.keras.optimizers.SGD(learning_rate=learning_rate, momentum=0.9)
train_step_fn = get_model_train_step_function(
detection_model, optimizer, to_fine_tune)이 데모에서는 data augmentation을 안하지만 random horizontal flipping과 random cropping을 통해 실험을 할 수 있습니다.
print('Start fine-tuning!', flush=True)
for idx in range(num_batches):
# random subset of examples을 위해 keys가져옵니다.
all_keys = list(range(len(train_images_np)))
random.shuffle(all_keys)
example_keys = all_keys[:batch_size]
gt_boxes_list = [gt_box_tensors[key] for key in example_keys]
gt_classes_list = [gt_classes_one_hot_tensors[key] for key in example_keys]
image_tensors = [train_image_tensors[key] for key in example_keys]
# Training step (forward pass + backwards pass)
total_loss = train_step_fn(image_tensors, gt_boxes_list, gt_classes_list)
if idx % 10 == 0:
print('batch ' + str(idx) + ' of ' + str(num_batches)
+ ', loss=' + str(total_loss.numpy()), flush=True)
print('Done fine-tuning!')Test image를 업로드 하고 새로운 모델로 inference 실행하기
test_image_dir = 'models/research/object_detection/test_images/ducky/test/'
test_images_np = []
for i in range(1, 50):
image_path = os.path.join(test_image_dir, 'out' + str(i) + '.jpg')
test_images_np.append(np.expand_dims(
load_image_into_numpy_array(image_path), axis=0))Input image에 detection을 실행합니다.
Args:
input_tensor: A [1, height, width, 3] Tensor of type tf.float32.
image는 model에 따라 resize할 수 있기 height과 width는 변동할 수 있습니다.
Returns: 3 Tensors (detection_boxes, detection_classes, detection_scores)가 담긴 딕셔너리
@tf.function
def detect(input_tensor):
preprocessed_image, shapes = detection_model.preprocess(input_tensor)
prediction_dict = detection_model.predict(preprocessed_image, shapes)
return detection_model.postprocess(prediction_dict, shapes)
처음 frame에서 tf.function을 실행하기 위해서는 시간이 좀 걸리지만 이후에는 빠르게 inference가 진행됩니다.
label_id_offset = 1
for i in range(len(test_images_np)):
input_tensor = tf.convert_to_tensor(test_images_np[i], dtype=tf.float32)
detections = detect(input_tensor)
plot_detections(
test_images_np[i][0],
detections['detection_boxes'][0].numpy(),
detections['detection_classes'][0].numpy().astype(np.uint32)
+ label_id_offset,
detections['detection_scores'][0].numpy(),
category_index, figsize=(15, 20), image_name="gif_frame_" + ('%02d' % i) + ".jpg")
imageio.plugins.freeimage.download()
anim_file = 'duckies_test.gif'
filenames = glob.glob('gif_frame_*.jpg')
filenames = sorted(filenames)
last = -1
images = []
for filename in filenames:
image = imageio.imread(filename)
images.append(image)
imageio.mimsave(anim_file, images, 'GIF-FI', fps=5)
display(IPyImage(open(anim_file, 'rb').read()))

'Studies & Courses > Machine Learning & Vision' 카테고리의 다른 글
| TensorFlow vs PyTorch vs Keras: A Beginner-Friendly Comparison of Deep Learning Frameworks (2) | 2025.05.14 |
|---|---|
| [Object Detection] Tensorflow Hub 활용하기 (inception resnet V2) (0) | 2021.03.31 |
| [Coursera 수료 ✅ ] DeepLearning.AI TensorFlow Developer (0) | 2021.03.25 |
| [ML 기초] 배치(batch)와 에포크(epoch) 차이 (0) | 2021.03.11 |
| 용어 구분 - 인공지능, 기계학습, 데이터과학, 빅데이터, 데이터마이닝, 에이전트 (0) | 2021.03.09 |




댓글