Contents
• Text Classification
• Naïve Bayes
– Formalizing the Naïve Bayes Classifier
– Naïve Bayes: Learning
– Multinomial Naive Bayes: A Worked Example
• Precision, Recall, and the F measure
• Text Classification – Evaluation
Text Classification
• Classification: assigning a class or category to an input
– e.g., "What is the subject of this article?"
• Text categorization
– Assigning a label to an entire text or document
– subject categories or topics labels
• Sentiment analysis
– Sentiment: the positive or negative orientation that a writer expresses toward some object
– e.g., “like”, “hate”, “neutral”
- "Positive or negative movie review?"
• Spam detection
– the binary classification task of assigning an email to spam or not-spam
• Authorship attribution (저자 판별)
– determining a text’s author
– e.g., "Who wrote which Federalist papers?"
• Age/gender identification
– e.g., "Male or female author?"
• Genre-detection
– e.g., "editorials" "movie-reviews" "news“
• Language Identificationa
Text Classification: definition
• Input:
– a document d
– a fixed set of classes C = {c1, c2,..., cJ}
• Output: a predicted class c ∈ C
Classification Methods: Handwritten rules
• Rules based on combinations of words or other features
– spam: black-list-address OR (“dollars” AND “have been selected”)
• Accuracy can be high
– If rules carefully refined by expert
• But building and maintaining these rules is expensive
Classification Methods: Supervised Machine Learning
• Input:
– a document d
– a fixed set of classes C = {c1, c2,..., cJ}
– A training set of m hand-labeled documents (Supervised)
(d1,c1),....,(dm,cm)
• Output:
– a learned classifier γ:d → c
– No free lunch: requires hand-classified training data
But data can be built up (and refined) by amateurs
Representing text for classification

- What is the best representation for the document d being classified?
- Simplest useful
Classification Methods: Supervised Machine Learning
Any kind of classifier
–Naïve Bayes
–Logistic regression
–Support-vector machines
–k-Nearest Neighbors
Naïve Bayes Intuition
•Simple (“naïve”) classification method based on Bayes rule
•Relies on very simple representation of document
–Bag of words (단어의 위치보다는 몇 번 나왔는가?, 하위 개념 : set(집합))
The Bag of Words Representation

Bayes’ Rule Applied to Documents and Classes
•For a document d and a class c
★

•To break down any conditional probability into three other probabilities
•Allows us to swap the conditioning P(c|d) ↔ P(d|c) (예) P(질병|증상) ↔ P(증상|질병)
•Sometimes easier to estimate one kind of dependence than the other
Naïve Bayes Classifier
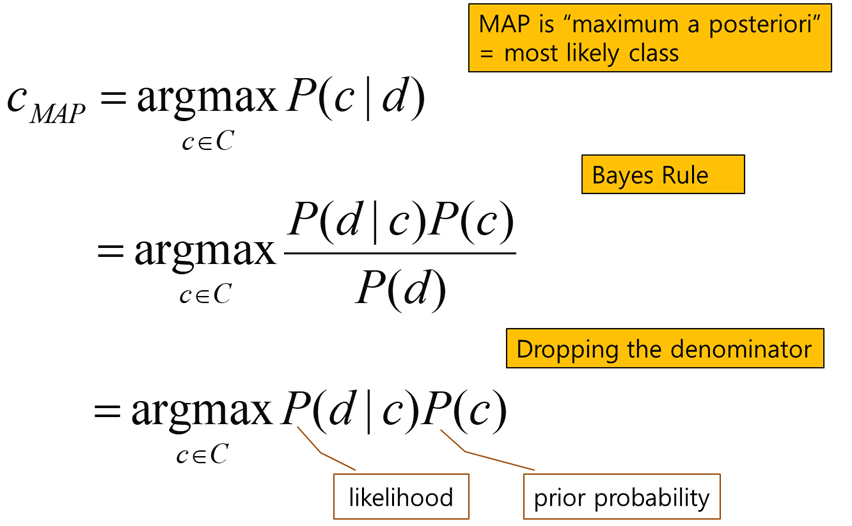


값을 최대로 만드는 카테고리를 찾겠다고 하는게 CMAP
MAP : MaximumMaximum A Posteriori
•P(x1,x2,…,xn|cj)
–O(|X|n•|C|) parameters
–Could only be estimated if a very, very large number of training examples was available.
Multinomial Naïve Bayes Independence Assumptions

•Bag of Words assumption:
–Assume position doesn’t matter
•Conditional Independence assumption
(naïve Bayes assumption):
–Assume the feature probabilities P(xi|cj) are independent given the class c.
모델을 다룰 수 있는 형태로 하기 위해 영향을 안 준다고 '가정'
체인룰로 풀어야 하나 영향을 안 준다고 가정하기 때문에 독립으로 표현
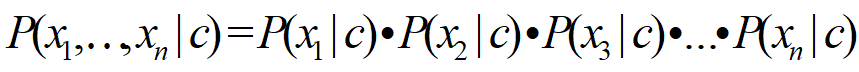
위와 같은 곱하기는 ∏ (product)로 표현
Multinomial Naïve Bayes Classifier
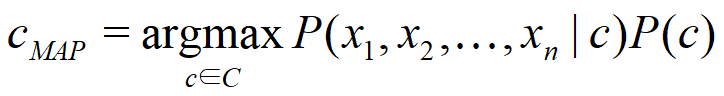

Naïve Bayes: Classifying
positions ← all word positions in test document

(예시) 정치의 확률값, 경제의 확률값, 과학의 확률값 중 가장 큰 것이 정치라면 해당 카테고리는 정치 카테고리가 된다.
Training the Naïve Bayes Classifier
•First attempt: maximum likelihood estimates
–simply use the frequencies in the data
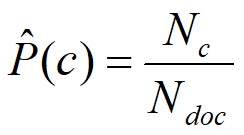
(예) 정치 = 2/100 = 0.2

(예) P(대통령|정치) = 대통령 단어 수 / 정치 카테고리의 모든 단어의 수
Problem with Maximum Likelihood
•What if we have seen no training documents with the word “fantastic” and classified as “positive”?
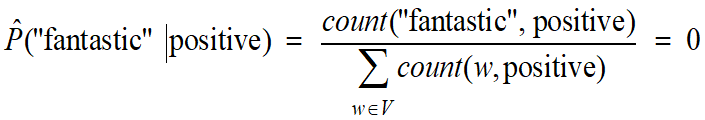
•Zero probabilities will cause the probability of the class to be zero, no matter the other evidence!

Laplace (add-1) smoothing for Naïve Bayes

add1 :모든 카운트에 1씩 더하라
확률의 총합이 1이 넘기 때문에 V(Vocabulary)의 총합을 분모에 둠
Handling unknown words and stop words
•Unknown words (미등록어)
–Words that occur in our test data but are not in our vocabulary (not occur in any training document)
–The solution is to ignore them – remove them from the test document and not include any probability for them at all
•Stop words
–Very frequent words like the and a
–Stop word list
· By sorting the vocabulary by frequency in the training set, and defining the top 10-100 vocabulary entries as stop words
· By using one of the many pre-defined stop word list available online
–Simply removed from both training and test documents
–However, using a stop word list doesn’t improve performance
→ it is more common to not use a stop word list
'Studies & Courses > NLP & Text Mining' 카테고리의 다른 글
| Building a Financial RAG Chatbot Using LLaMA, Streamlit and RunPod (VSCode) (1) | 2025.05.16 |
|---|---|
| [Text Mining] Text Reprocessing (0) | 2020.04.02 |
| [Text Mining] Introduction to Text Mining (0) | 2020.03.30 |



댓글